
SDL GPU API Concepts: Data Transfer and Cycling
2024-08-28
Ever since the FNA team’s GPU API proposal got approved, the concept I get the most questions about by far is cycling. This is definitely the most unique and conceptually nuanced aspect of our API, so I would like to go into some detail about it here and hopefully clear up the questions people have about it.
To understand cycling, why we implement it in our API, and when and why you should use it, we have to explain modern rendering in general.
The command buffer
The most important thing to remember when dealing with rendering is that the GPU is a separate device from the CPU. It has a completely different execution timeline from the CPU.
Because of this, most rendering-related operations are asynchronous. This means when you tell a graphics API to do something from your code, the GPU is not executing that command immediately, nor is the CPU waiting for the results of the command. Why should it? A separate device is doing the work, so the CPU can continue on its merry way. Imagine if every time you sent some mail, you sat by the mailbox until you got a response. Wouldn’t you want to do something else in the meantime?
In older APIs like OpenGL, your commands are inserted into the graphics context’s command stream linearly. In newer APIs, like the ones SDL_GPU supports, the asynchronicity is made more explicit to the client - you insert commands into a command buffer on the CPU, and then submit the command buffer to the GPU when you are ready for those commands to begin executing.
The advantages of this structure are clear. Since graphics state is localized to the command buffer instead of the entire graphics context, clean multi-threaded setups are now possible, and it’s much easier to keep track of state changes.
Since execution is asynchronous, we have a problem to deal with - data synchronization.
Data synchronization
Let’s have a look at the following innocent little snippet of pseudocode.
GraphicsDevice_SetBufferData(myVertexBuffer, ...); // write to a buffer region
GraphicsDevice_BindVertexBuffer(myVertexBuffer);
GraphicsDevice_Draw(...);
GraphicsDevice_SetBufferData(myVertexBuffer, ...); // write to the same buffer region
This is the stuff that keeps graphics programmers up at night. Obviously the client intended to use the data from their first data write in the draw call. But now they are immediately asking to overwrite the data. Remember that commands are asynchronous and we don’t know when they will be executed or finished, so the draw call has probably not finished before the second time the buffer is written to.
What are we to do?
Option 1 - Execute all commands up to now and stall until they finish.
This is really bad for performance. Remember that mailbox analogy from before?
Option 2 - Ignore the issue and hope for the best.
This is definitely going to lead to visual errors.
Option 3 - Assert
Aggressively let the client know they shouldn’t overwrite the data on a buffer after issuing a draw call with it. The client will be forced to rewrite their code. That’s valid, but also annoying and inflexible.
Option 4 - Resource renaming
The implementation switches to a new buffer, performs the SetData call on the new buffer, and swaps the references. This process is invisible to the client.
Option 4 is clearly the best - it has good performance, prevents visual errors, and the client doesn’t have to do tedious buffer management.
We have designed SDL_GPU around Option 4, with a few little tweaks. Before we can get into that, we have to talk about the data transfer process in general.
Data Integrity
This is how you create a vertex buffer using SDL_GPU in C:
SDL_GPUBuffer *myVertexBuffer = SDL_CreateGPUBuffer(
myDevice,
&(SDL_GPUBufferCreateInfo){
.usageFlags = SDL_GPU_BUFFERUSAGE_VERTEX_BIT,
.sizeInBytes = sizeof(MyVertexStruct) * 6
}
);
Naturally, you will want to put data into your buffers. In SDL_GPU, transferring data to and from buffers is accomplished via a SDL_GPUTransferBuffer.
SDL_GPUTransferBuffer *myTransferBuffer = SDL_CreateGPUTransferBuffer(
myDevice,
&(SDL_GPUTransferBufferCreateInfo){
.usage = SDL_GPU_TRANSFERBUFFERUSAGE_UPLOAD,
.sizeInBytes = sizeof(MyVertexStruct) * 6
}
);
To put data into your transfer buffers, you will have to do a map call. Mapping returns a CPU-accessible pointer to the transfer buffer data.
void *transferDataPtr = SDL_MapGPUTransferBuffer(
myDevice,
myTransferBuffer,
SDL_FALSE // the cycle parameter
);
Let’s conveniently ignore that cycle parameter for now. The map operation happens immediately when you call it - it’s on the CPU timeline. The pointer that you receive can be used normally. It’s just a data pointer.
PositionTextureVertex* transferData = (PositionTextureVertex*)transferDataPtr;
transferData[0] = (PositionTextureVertex) { -1, -1, 0, 0, 0 };
transferData[1] = (PositionTextureVertex) { 1, -1, 0, 1, 0 };
transferData[2] = (PositionTextureVertex) { 1, 1, 0, 1, 1 };
transferData[3] = (PositionTextureVertex) { -1, -1, 0, 0, 0 };
transferData[4] = (PositionTextureVertex) { 1, 1, 0, 1, 1 };
transferData[5] = (PositionTextureVertex) { -1, 1, 0, 0, 1 };
You could also have this data living somewhere else and call SDL_memcpy to put it in the transfer buffer, but this approach avoids an extra data copy.
When you are done assigning data, you unmap:
SDL_UnmapGPUTransferBuffer(myDevice, myTransferBuffer);
Once you unmap, the data pointer is no longer valid.
Now that you have data in your transfer buffer, you can transfer the data to your vertex buffer.
SDL_GPUCommandBuffer* cmdBuf = SDL_AcquireGPUCommandBuffer(context->Device);
SDL_GPUCopyPass* copyPass = SDL_BeginGPUCopyPass(cmdBuf);
SDL_UploadToGPUBuffer(
copyPass,
&(SDL_GPUTransferBufferLocation) {
.transferBuffer = myTransferBuffer,
.offset = 0
},
&(SDL_GPUBufferRegion) {
.buffer = VertexBuffer,
.offset = 0,
.size = sizeof(PositionTextureVertex) * 6
},
SDL_FALSE // another cycle parameter...
);
SDL_EndGPUCopyPass(copyPass);
Unlike the map operation, uploading to a buffer occurs on the GPU timeline. This means that the data will not be copied immediately, but only once the GPU decides to execute that command.
Let’s refer back to that problematic pseudocode, but with SDL calls this time…
SDL_MapGPUTransferBuffer(...)
// set transfer data here
SDL_UnmapGPUTransferBuffer(...)
// upload data
SDL_BeginGPUCopyPass(...)
SDL_UploadToGPUBuffer(...)
SDL_EndGPUCopyPass(...)
// draw using uploaded data
SDL_BeginGPURenderPass(...)
SDL_BindGPUVertexBuffers(...)
SDL_DrawGPUPrimitives(...)
SDL_EndGPURenderPass(...)
// upload more data to the same buffer region
SDL_BeginGPUCopyPass(...)
SDL_UploadToGPUBuffer(...)
SDL_EndGPUCopyPass(...)
This actually isn’t a problem for SDL_GPU. The visual output will be correct. Why is that? The reason is memory barriers. Barriers ensure that data is not overwritten until all the commands that depend on that data are finished executing on the GPU. This synchronization occurs on the GPU, so no CPU stalling is required to ensure data integrity. This is a major advantage of the command buffer and transfer buffer model.
As a client of SDL_GPU, you don’t have to worry about barriers explicitly. We insert appropriate barriers for you.
However, the success of the above pseudocode depends on the fact that the data in the transfer buffer doesn’t change. Remember that modifying data on the transfer buffer happens immediately on the CPU timeline. Now we’ll have basically the same problem as before - if the client modifies data in the transfer buffer before the upload commands run on the GPU, the data that ends up in the buffers will be incorrect.
This is where cycling comes in.
Cycling
You might think that our SDL_GPUBuffers correspond to an actual buffer object in the underlying graphics API (VkBuffer, MTLBuffer, etc). But we lie to you. Sorry! But it’s for your own good.
This is the internal struct that we actually hand back to you from Metal, as an example:
typedef struct MetalBufferContainer
{
MetalBuffer *activeBuffer;
Uint32 size;
Uint32 bufferCapacity;
Uint32 bufferCount;
MetalBuffer **buffers;
SDL_bool isPrivate;
SDL_bool isWriteOnly;
char *debugName;
} MetalBufferContainer;
In other words, the SDL_GPUBuffer is actually a container of internal buffers. When you first create a buffer or texture, it only has one internal resource, which is the active resource.
When you reference a resource like a SDL_GPUBuffer in a command, we consider its internal active resource to be bound to the command buffer. When an internal resource is no longer referenced by any pending or active command buffer, it is considered unbound. Internal resources become unbound as the command buffers that bind them are completed.
When you submit a GPUBuffer for use with a command, the active buffer within that GPUBuffer is selected for use with the command.
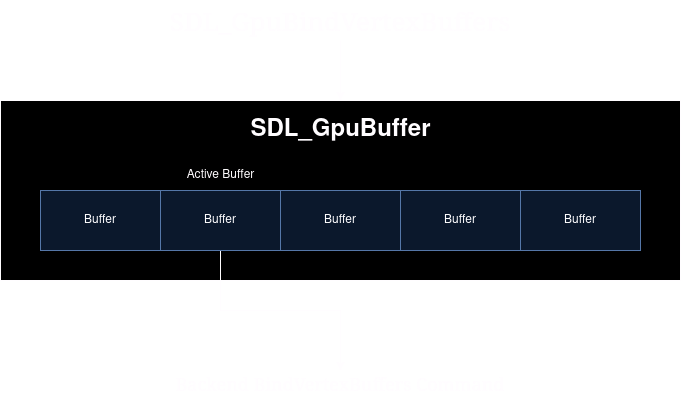
Every operation in SDL_GPU that involves writing to a data resource has a cycle parameter. If the cycle parameter is set to SDL_TRUE and the current active resource is bound, then we select the next unbound internal resource as the new active resource.
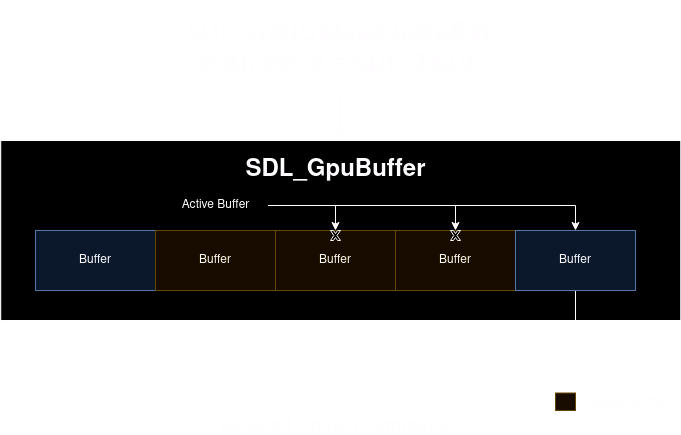
If all internal resource are bound, a new one is created and set as the active resource.
With all this in mind - remember that warning I gave about modifying transfer buffers before the commands are finished? With cycling, you don’t have to worry about that at all:
void *dataPtr = SDL_MapGPUTransferBuffer(myTransferBuffer, SDL_FALSE)
// set data safely, without corrupting previous uploads
SDL_UnmapGPUTransferBuffer(myTransferBuffer)
SDL_BeginGPUCopyPass(...)
SDL_UploadToGPUBuffer(myTransferBuffer, myVertexBuffer)
SDL_EndGPUCopyPass(...)
SDL_BeginGPURenderPass(...)
SDL_BindGPUVertexBuffers(myVertexBuffer)
SDL_DrawGPUPrimitives(...)
SDL_EndGPURenderPass(...)
dataPtr = SDL_MapGPUTransferBuffer(myTransferBuffer, SDL_TRUE) // cycle the transfer buffer!
// set data safely, without corrupting the upload command above
SDL_UnmapGPUTransferBuffer(myTransferBuffer)
Because we cycled on the second map call, the data being used by the upload command is preserved, and we can safely write to the transfer buffer again. Remember: because transfer buffer updates occur on the CPU timeline, memory barriers won’t save you like they would with GPU timeline operations.
So… if we have memory barriers, why would we bother cycling on operations that write on the GPU timeline?
Data Dependencies
Cycling has one more use beyond ensuring data integrity: it breaks data dependencies between frames.
Every time you call SDL_GPUSubmit, commands are appended to the GPU command queue. This means that you can submit commands continuously without worrying about if the GPU is done doing anything yet. If the GPU is having trouble keeping up with the CPU submitting commands (we call this being GPU-bound), it could be working on multiple frame submissions simultaneously.
The GPU is allowed to reorder commands and execute them out of order, as long as it respects memory barriers. On certain systems, render, compute, and transfer work can even be executed simultaneously, so smart drivers will move work between these queues to maximize efficiency. GPUs are at their best when they can parallelize as much work as possible.
Let’s say that every frame, you begin a render pass using a specific texture by clearing it, and then you blit it to the swapchain texture. This means that the GPU has to wait for the current command buffer to end before it can work on the next one - there is a data dependency between the two frames.
If you cycle that texture when the render pass begins, the GPU doesn’t have to wait for any previous commands using that texture to finish before it can start working on new commands - after cycling, the render pass uses a different internal texture. The data dependency between frames is broken.
This same principle applies to any frequently-updated resource, like a buffer which has data uploaded to it every frame. If you break the data dependencies between frames, the GPU can reorder its work as efficiently as possible. This has the potential to improve your throughput in GPU-bound scenarios.
When Not To Cycle
At this point, you’re probably thinking that cycling sounds pretty great and fixes all of your problems. But there are times when it’s important not to cycle.
It is extremely important to note that since cycling switches the active internal resource, the existing contents of the resource are not preserved. Cycling doesn’t undefine already bound data, but when cycling you must treat all of the data in the resource as being undefined for any subsequent command until the data is written again.
When beginning a render pass, for each attachment in the pass you are given the option to load, clear, or not care. If you are loading that means you care about the contents of the texture, and thus cycling would be nonsense because it implicitly discards the data in the texture. This principle applies more generally - any time you want to preserve the existing data in a resource, you should not cycle.
Consider the case where you are updating different regions of the same vertex buffer with separate Upload calls. If you cycled the vertex buffer in between these Upload calls, all the previously updated regions would contain garbage data. This is definitely not what you want.
Best Practices
I went into a lot of internal implementation details here, but when using the API you don’t have to keep any of that in mind. Just remember the following two rules when cycling a resource:
- Previous commands using the resource have their data integrity preserved.
- The data in the resource is undefined for subsequent commands until it is written to.
Hopefully you now have an understanding of cycling and when to use it!
To summarize some generally useful best practices:
- For transfer buffers that are used every frame, cycle on the first Map call of the frame.
- Cycle transfer buffers whenever they might be overwriting in-flight data.
- For buffers that are overwritten every frame, cycle on the first upload of the frame.
- For textures used in render passes and overwritten every frame, cycle on the first render pass usage of the frame.
- Upload all dynamic buffer data early in the frame before you do any render or compute passes.
- Do not cycle when you care about the existing contents of a resource.